How to Read Cosmosdb Data From Node.js
Using Node.js to Read Really, Actually Large Datasets & Files (Pt 1)

This web log postal service has an interesting inspiration point. Last calendar week, someone in 1 of my Slack channels, posted a coding challenge he'd received for a developer position with an insurance technology company.
It piqued my interest every bit the challenge involved reading through very big files of data from the Federal Elections Commission and displaying back specific data from those files. Since I've non worked much with raw information, and I'm ever up for a new challenge, I decided to tackle this with Node.js and come across if I could complete the challenge myself, for the fun of information technology.
Here'south the iv questions asked, and a link to the data set that the program was to parse through.
- Write a program that will impress out the full number of lines in the file.
- Find that the eighth cavalcade contains a person's name. Write a programme that loads in this data and creates an array with all name strings. Print out the 432nd and 43243rd names.
- Notice that the 5th cavalcade contains a class of engagement. Count how many donations occurred in each month and print out the results.
- Notice that the 8th column contains a person'southward name. Create an array with each start name. Place the nigh mutual commencement name in the data and how many times it occurs.
Link to the data: https://world wide web.fec.gov/files/bulk-downloads/2018/indiv18.goose egg
When yous unzip the folder, you should run across one main .txt file that's two.55GB and a folder containing smaller pieces of that main file (which is what I used while testing my solutions earlier moving to the main file).
Not likewise terrible, right? Seems doable. So let's talk about how I approached this.
The 2 Original Node.js Solutions I Came Up With
Processing big files is nothing new to JavaScript, in fact, in the core functionality of Node.js, there are a number of standard solutions for reading and writing to and from files.
The most straightforward is fs.readFile() wherein, the whole file is read into retentivity and and then acted upon once Node has read it, and the second option is fs.createReadStream(), which streams the information in (and out) similar to other languages like Python and Coffee.
The Solution I Chose to Run With & Why
Since my solution needed to involve such things as counting the full number of lines and parsing through each line to go donation names and dates, I chose to utilise the 2d method: fs.createReadStream(). So, I could use the rl.on('line',...) function to get the necessary data from each line of lawmaking as I streamed through the document.
Information technology seemed easier to me, than having to split apart the whole file in one case information technology was read in and run through the lines that fashion.
Node.js CreateReadStream() & ReadFile() Code Implementation
Below is the code I came upwardly with using Node.js'south fs.createReadStream() part. I'll break information technology down beneath.
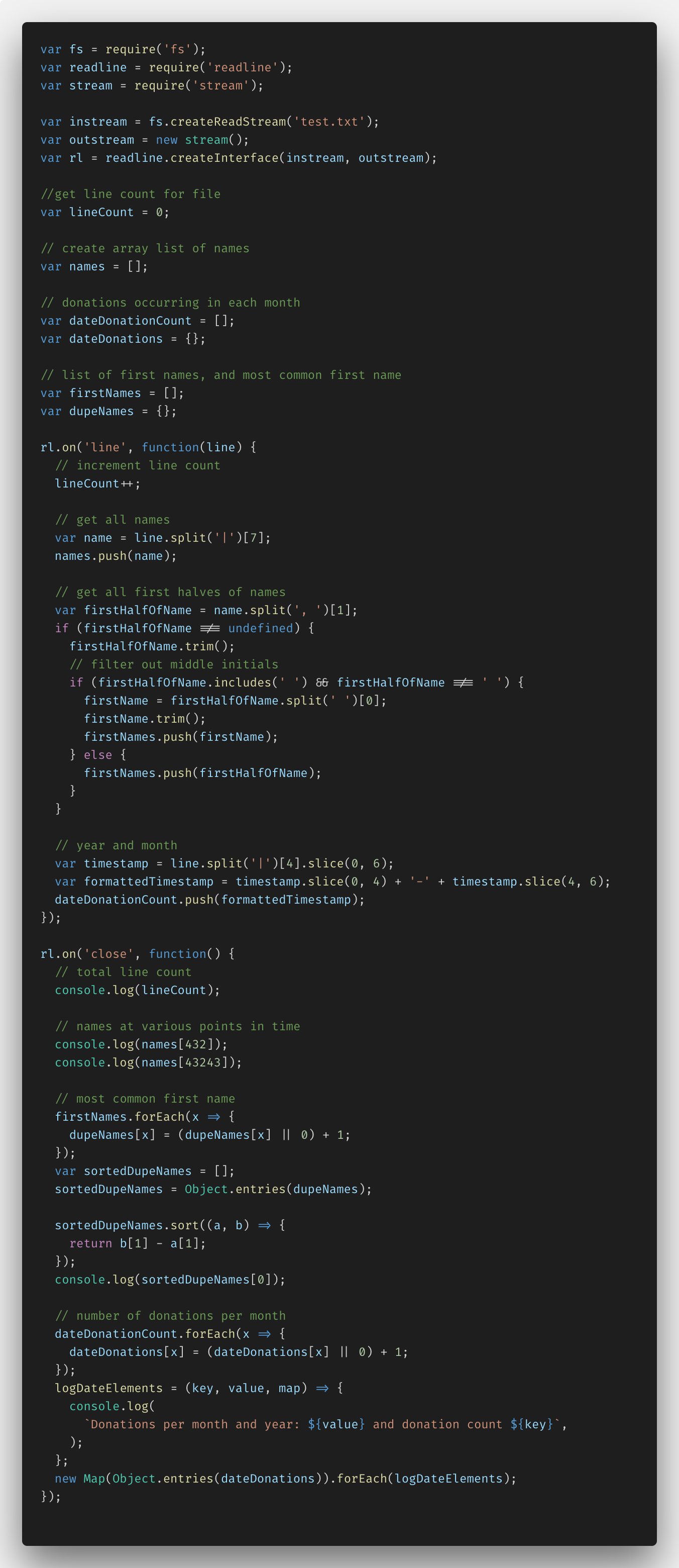
The very outset things I had to practise to set this upward, were import the required functions from Node.js: fs (file organization), readline, and stream. These imports allowed me to then create an instream and outstream and so the readLine.createInterface(), which would permit me read through the stream line past line and print out information from it.
I also added some variables (and comments) to concur various $.25 of data: a lineCount, names assortment, donation array and object, and firstNames array and dupeNames object. You'll come across where these come into play a little later.
Within of the rl.on('line',...) part, I was able to exercise all of my line-by-line data parsing. In here, I incremented the lineCount variable for each line it streamed through. I used the JavaScript split() method to parse out each name and added information technology to my names assortment. I further reduced each name down to just first names, while accounting for middle initials, multiple names, etc. forth with the get-go proper name with the help of the JavaScript trim(), includes() and split() methods. And I sliced the year and appointment out of date cavalcade, reformatted those to a more readable YYYY-MM format, and added them to the dateDonationCount array.
In the rl.on('close',...) function, I did all the transformations on the data I'd gathered into arrays and console.logged out all my data for the user to see.
The lineCount and names at the 432nd and 43,243rd alphabetize, required no further manipulation. Finding the about common proper noun and the number of donations for each calendar month was a little trickier.
For the nearly mutual first name, I first had to create an object of primal value pairs for each proper name (the key) and the number of times it appeared (the value), and so I transformed that into an array of arrays using the ES6 function Object.entries(). From there, information technology was a simple task to sort the names by their value and print the largest value.
Donations as well required me to make a similar object of key value pairs, create a logDateElements() function where I could nicely using ES6's string interpolation to brandish the keys and values for each donation month. And then create a new Map() transforming the dateDonations object into an assortment of arrays, and looping through each array calling the logDateElements() role on it. Whew! Not quite equally simple as I starting time idea.
But it worked. At least with the smaller 400MB file I was using for testing…
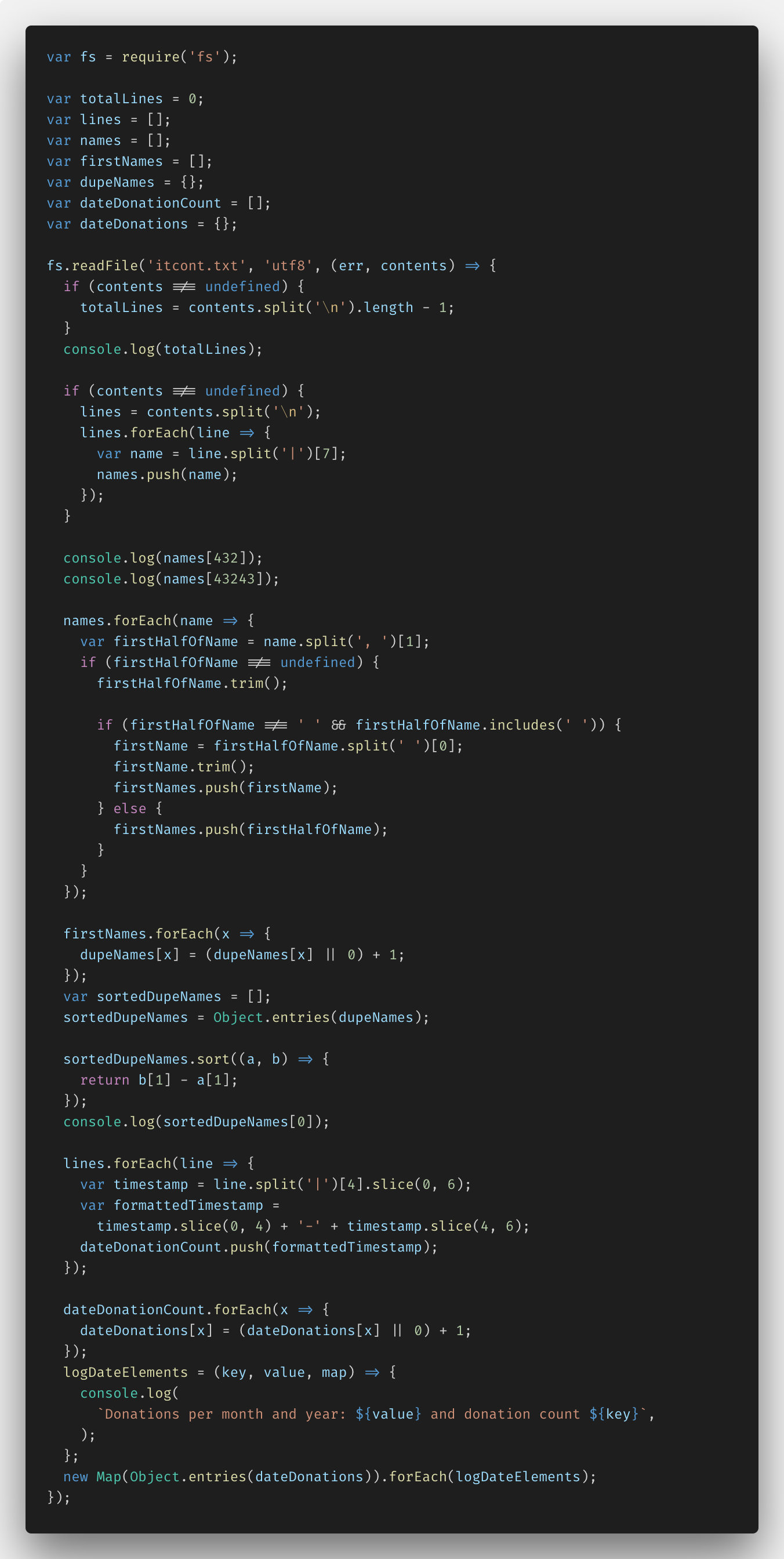
Later on I'd done that with fs.createReadStream(), I went back and also implemented my solutions with fs.readFile(), to see the differences. Here's the code for that, only I won't go through all the details hither — information technology's pretty similar to the first snippet, simply more synchronous looking (unless you use the fs.readFileSync() role, though, JavaScript will run this code just as asynchronously as all its other lawmaking, not to worry.
If you'd similar to come across my full repo with all my code, y'all tin come across it hither.
Initial Results from Node.js
With my working solution, I added the file path into readFileStream.js file for the 2.55GB monster file, and watched my Node server crash with a JavaScript heap out of retentivity error.
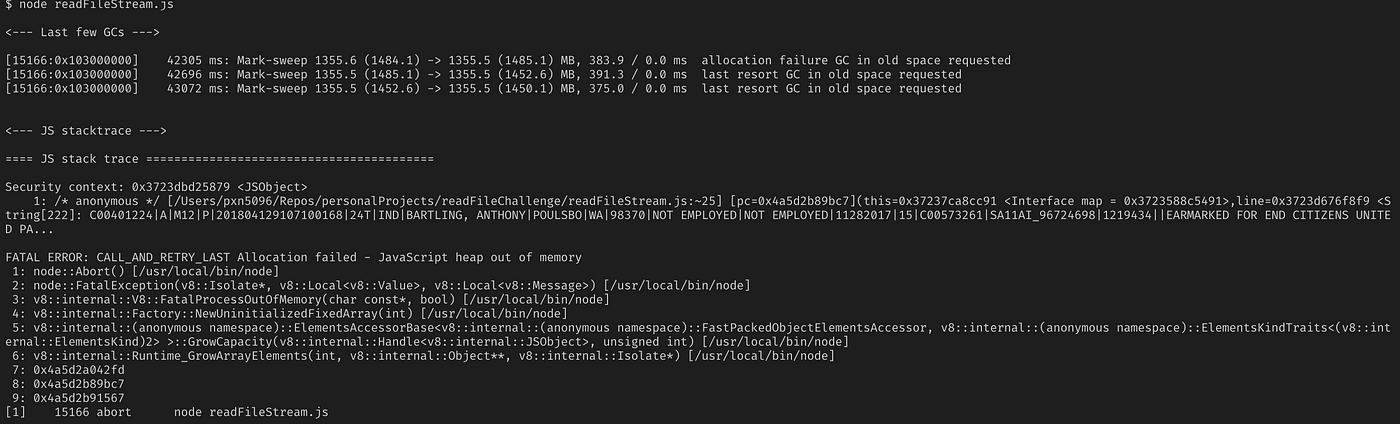
As it turns out, although Node.js is streaming the file input and output, in between it is still attempting to concur the entire file contents in memory, which information technology can't practice with a file that size. Node can agree up to 1.5GB in memory at one fourth dimension, but no more.
So neither of my electric current solutions was upward for the full challenge.
I needed a new solution. A solution for fifty-fifty larger datasets running through Node.
The New Information Streaming Solution
I found my solution in the class of EventStream, a popular NPM module with over 2 one thousand thousand weekly downloads and a promise "to brand creating and working with streams easy".
With a picayune aid from EventStream's documentation, I was able to effigy out how to, once more, read the lawmaking line past line and do what needed to be done, hopefully, in a more than CPU friendly way to Node.
EventStream Lawmaking Implementation
Here'due south my lawmaking new lawmaking using the NPM module EventStream.
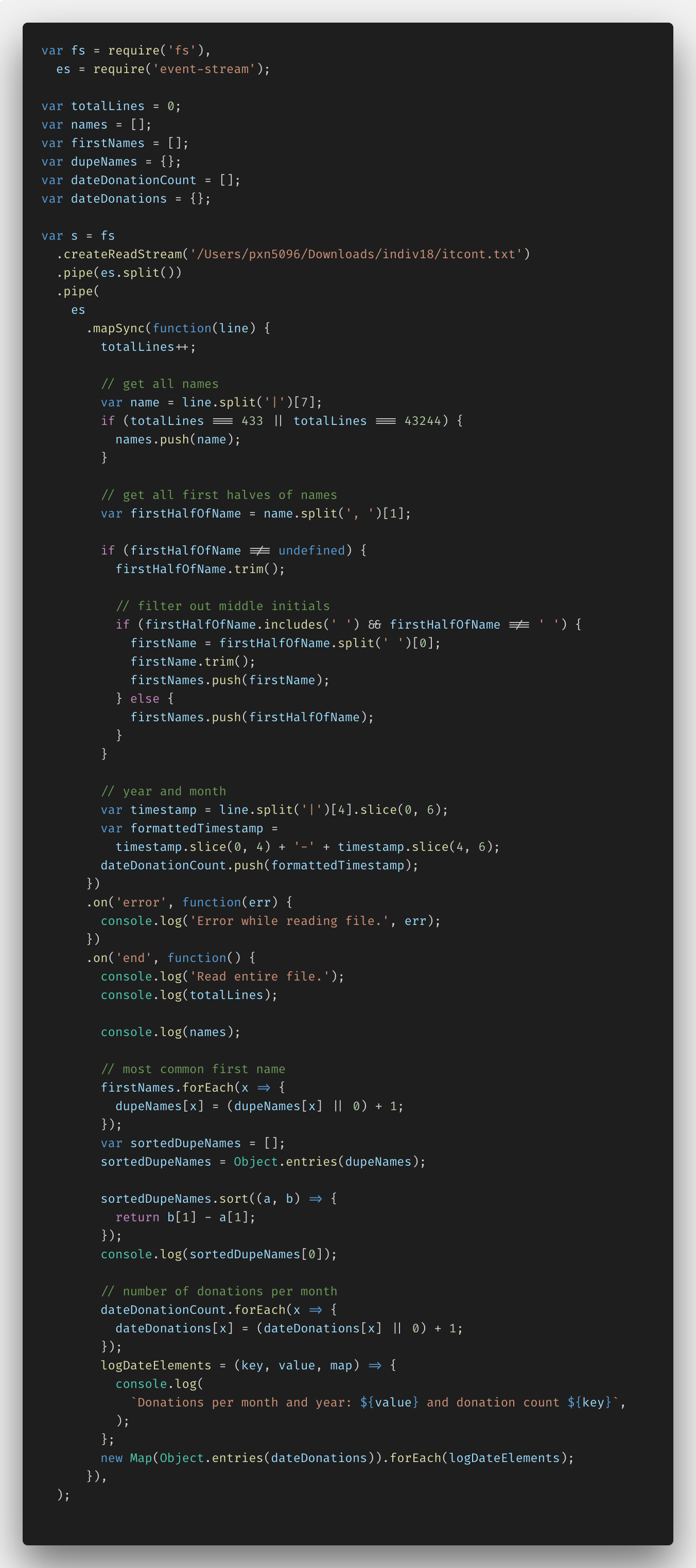
The biggest alter was the pipe commands at the beginning of the file — all of that syntax is the way EventStream'southward documentation recommends you lot break up the stream into chunks delimited by the \north character at the end of each line of the .txt file.
The but other thing I had to change was the names answer. I had to fudge that a footling flake since if I tried to add together all 13MM names into an array, I again, hit the out of memory effect. I got around it, by just collecting the 432nd and 43,243rd names and adding them to their own array. Not quite what was existence asked, but hey, I had to get a little artistic.
Results from Node.js & EventStream: Circular 2
Ok, with the new solution implemented, I again, fired up Node.js with my two.55GB file and my fingers crossed this would work. Check out the results.
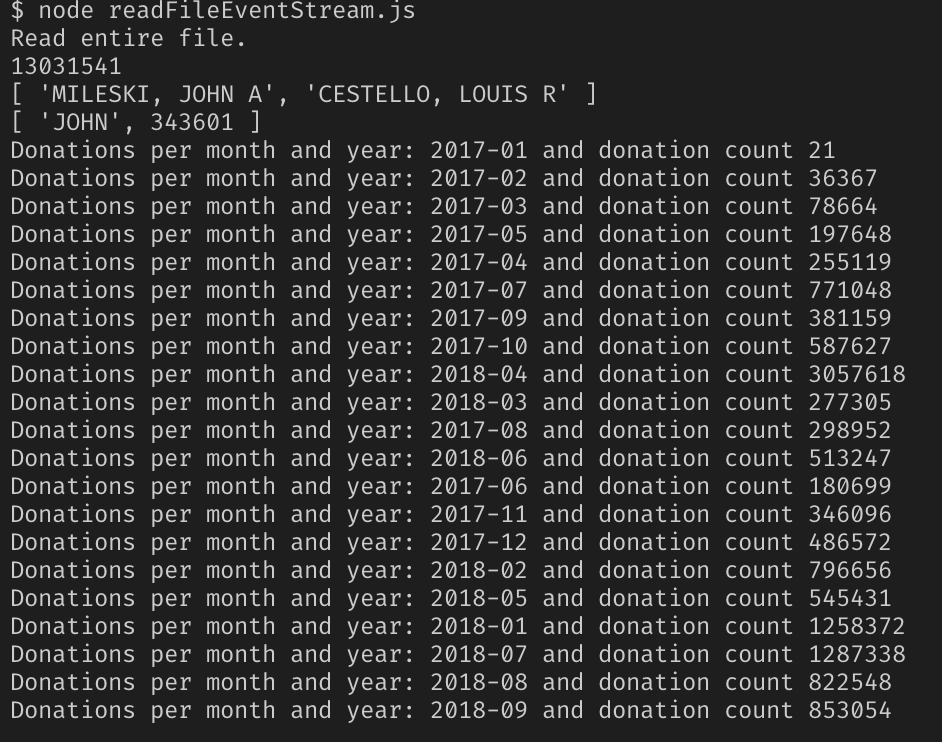
Success!
Determination
In the terminate, Node.js'south pure file and big data handling functions barbarous a little short of what I needed, only with just one extra NPM package, EventStream, I was able to parse through a massive dataset without crashing the Node server.
Stay tuned for part ii of this series where I compare my 3 different ways of reading data in Node.js with performance testing to see which one is truly superior to the others. The results are pretty eye opening — peculiarly as the data gets larger…
Thanks for reading, I promise this gives you an idea of how to handle large amounts of information with Node.js. Claps and shares are very much appreciated!
If you enjoyed reading this, you lot may also savour some of my other blogs:
- Postman vs. Insomnia: Comparing the API Testing Tools
- How to Utilise Netflix's Eureka and Leap Cloud for Service Registry
- Jib: Getting Adept Docker Results Without Any Noesis of Docker
hosmerpicamortiver1974.blogspot.com
Source: https://itnext.io/using-node-js-to-read-really-really-large-files-pt-1-d2057fe76b33
0 Response to "How to Read Cosmosdb Data From Node.js"
Post a Comment